Following two previous blog posts about data modeling with Redis (Data Types Visualization and German Postcodes Geoposition) this post advances the German Postcodes data model by adding the ability to scan not only by German postcodes ("Postleitzahlen", short PLZ, e.g. 45130) but also for city names (e.g. Essen) and by adding the ability to query for the distance between two postcodes.
Use Case - Advanced
As mentioned in the previous blog post the main use case now (in the advanced data model) is to have a select drop-down on a website where you can enter a German postcode (e.g. 45130) or a so-called "Leitregion", lead region, (e.g. 45), or (now) a city name pattern and then receive an option list of all cities for the given input. Upon selecting one option you can then query for:
- the geoposition of this postcode (
array) - the (
json) object with further information on this postcode - a list (
array) of all postcodes and city names within the given input - and (now) the linear distance between two postcodes' central points (
array)
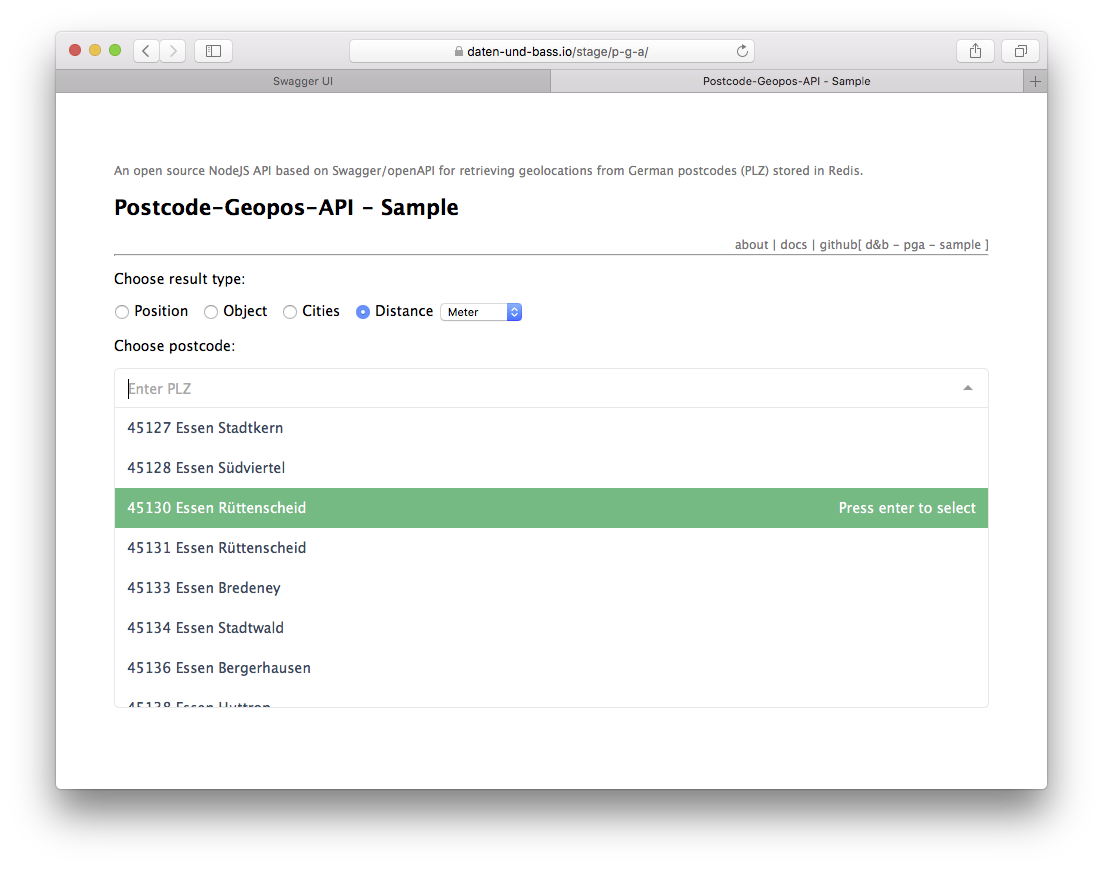
See the updated sample client implementation, based on vuejs and vue-multiselect can be found here.
Advancements
Overview:
"Data Types" , "Naming/Prefixes" and the "Stack for the API Server" as mentioned in the previous blog post remain unchanged.
However, there are new additions to these:
- the sorted set
de:postcodes:nameswill now be accessible byZSCAN - and the sorted set
de:postcodes:positionscan now be queried byGEODIST
to query for the (linear) distance between two postcodes' central points
All these commands are also available in NodeJS in the npm module redis.
This is the Swagger/openApi docs:
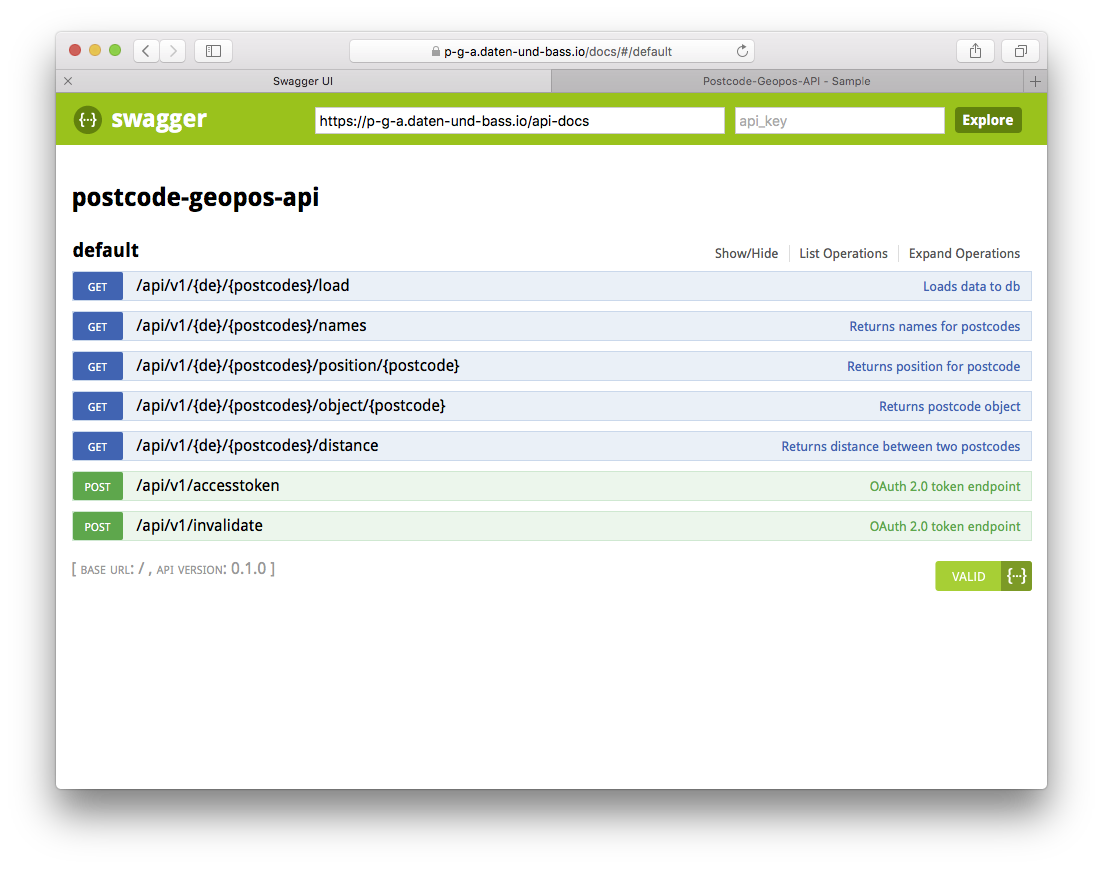
Details
The following section covers some details on these additions and provides sample redis-cli commands along with quotes from the official Redis command documentation.
de:postcodes:names
Just to refresh your memory:
One sorted set of postcodes with city names (all with the same score of 0 to have lexicographical ordering by postcode):
ZADD de:postcodes:names 0 "45130 Essen Rüttenscheid"
"Adds all the specified members with the specified scores to the sorted set stored at key".
Advancement:
The first advancement addresses the "main caveat" mentioned at the end of the "Data Model Discussion" section in the previous blog post: That is, if modeled like that, user input has to be the postcode itself (at least in order to have the performance advantage of the sorted set's lexicographical ordering by postcode).
Now a scan is "dared" (for now) ... and despite the required pattern matching across the whole set (of almost 13,000 members) it seems to work so far:
ZSCAN de:postcodes:names 0 MATCH *[Ee]sse* COUNT 10
"The SCAN command and the closely related commands SSCAN, HSCAN and ZSCAN are used in order to incrementally iterate over a collection of elements"
"ZSCAN iterates elements of Sorted Set types and their associated scores."
Count 10 is the default value and could be omitted above.
However, if you want Redis to iterate through all items (here almost 13,000) in one iteration, then it is
ZSCAN de:postcodes:names 0 MATCH *[Ee]sse* COUNT 13000
Otherwise, if you want to incrementally iterate over this sorted set with the amount of e.g. COUNT 250 you would do:
ZSCAN de:postcodes:names <new_cursor> MATCH *[Ee]sse* COUNT 250
Where <new_cursor> is 0 in the first call and changed to the corresponding return value in consecutive calls ... so often until its return value comes back as 0. An example for SCAN in the node_redis module can be found here.
The return value of ZSCAN is an array where the first element is the current cursor and the second element is another array of elements found so far (the member and its associated score):
# First call with 0:
ZSCAN de:postcodes:names 0 MATCH *[Ee]sse* COUNT 250
1) "2208" # <new_cursor>
2) 1) "53506 Kesseling H\xc3\xb6nningen Altenahr" # member
2) "0" # score
3) "87640 H\xc3\xb6llenbauer Biessenhofen"
4) "0"
5) "57587 Birken-Honigsessen Wissen"
6) "0"
# Next call with 2208:
ZSCAN de:postcodes:names 2208 MATCH *[Ee]sse* COUNT 250
1) "15248"
2) 1) "55270 Ober-Olm Jugenheim in Rheinhessen Nieder-Olm"
2) "0"
3) "45276 Essen Steele"
4) "0"
5) "81829 M\xc3\xbcnchen Bezirksteil Messestadt Riem"
6) "0"
7) "45136 Essen Bergerhausen"
8) "0"
9) "45307 Essen Kray"
10) "0"
# Next call with 15248 ...
You can read more on ZSCAN in the SCAN documentation.
The alternative to this somehow "expensive" pattern matching during ZSCAN could e.g. have been another sorted set with the inversed scheme (city name first and then postcode), e.g.:
ZADD de:postcodes:names 0 "Essen Rüttenscheid 45130"
But why not try to challenge Redis ;-> ... And the total amount of 13,000 members is probably ridiculous to Redis' capabilities anyway.
de:postcodes:positions
Just to refresh your memory:
One sorted set of postcodes only (score calculated from latitude and longitude as geohash):
GEOADD de:postcodes:positions 51.43758188556734012 7.00937658548355103 "45130"
"Adds the specified geospatial items (latitude, longitude, name) to the specified key."
Advancement:
The second advancement compared to the initial post is that now it is possible to query the linear distance between two postcodes' central points.
GEODIST de:postcodes:positions 45130 40479 m
"Return the distance between two members in the geospatial index represented by the sorted set."
"The
unitmust be one of the following, and defaults to meters:mfor meters,kmfor kilometers,mifor miles, orftfor feet.
GEODIST de:postcodes:positions 45130 40479
"27673.8417"
So for returning the value in kilometers:
GEODIST de:postcodes:positions 45130 40479 km
"27.6738"
You can read more on GEODIST in its docs.
This of course (for now) only offers the opportunity to query between postcodes and not e.g. for something more precise like streets and street numbers ... but one step at a time.
But even with the little information provided here, you could save (maybe expensive, yet repetitive) API calls elsewhere (e.g. as for always querying the same city lists) and use the information provided here as a starting point for other APIs where more detailed information is available.
Further Information:
Redis:
https://redis.io/topics/data-types
https://redis.io/commands
https://redis.io/commands/scan
https://redis.io/commands/geodist
https://www.npmjs.com/package/redis
https://daten-und-bass.io/blog/data-modeling-with-redis-german-postcodes-geoposition/
https://daten-und-bass.io/blog/data-modeling-with-redis-data-types-visualization/
VueJS Component: vue-multiselect:
https://github.com/shentao/vue-multiselect
https://vuejs.org
Postcode Geopos API: Live demos
https://daten-und-bass.remotedocker/stage/p-g-a/
https://p-g-a.daten-und-bass.io/docs/
Postcode Geopos API: Source code
https://github.com/daten-und-bass/p-g-a_sample
https://github.com/daten-und-bass/postcode-geopos-api